Can LLMs Self-critiquing Their Own Answers?
Self-correction/critiquing is a methodology proposed to improve the accuracy and appropriateness of the generated content by Large Language Models (LLMs). It involves an LLM reviewing its own responses, identifying problems or errors, and revising its answers accordingly.
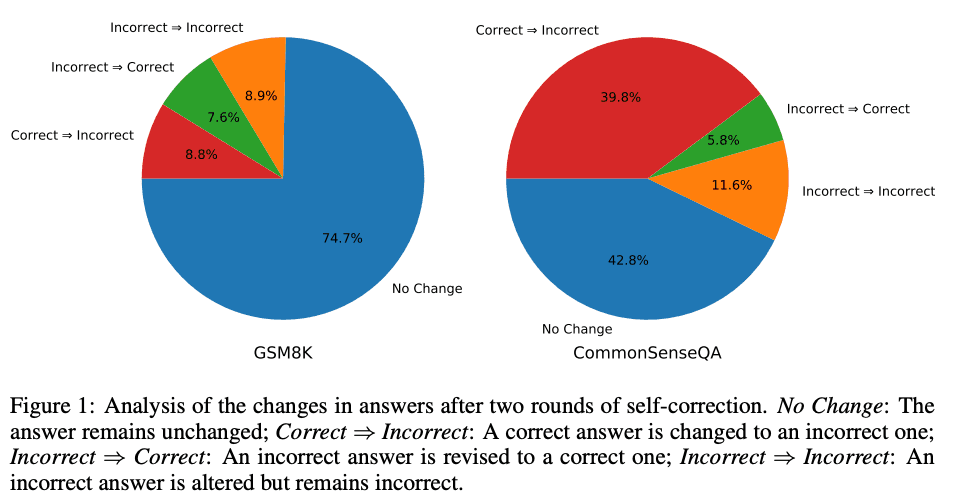
But, If an LLM possesses the ability to self-correct, why doesn’t it simply offer the correct answer in its initial attempt?
In this month (October), two research papers showed that LLMs are not yet capable of self-correcting their reasoning basically because LLMs cannot verify the solution.
Moreover, the iterative mode, where the question and the generated answer are feedback to the LLM over and over is degrading the quality of the answer significantly.

References:
LARGE LANGUAGE MODELS CANNOT SELF-CORRECT REASONING YET: by J Huang et. al
GPT-4 Doesn't Know It's Wrong: An Analysis of Iterative Prompting for Reasoning Problems: by K Valmeekam et. all