Document Order and Retrieval Strategies for Enhanced LLM Performance
Language models often struggle to use information in the middle of long input contexts, and that performance decreases as the input context grows longer.
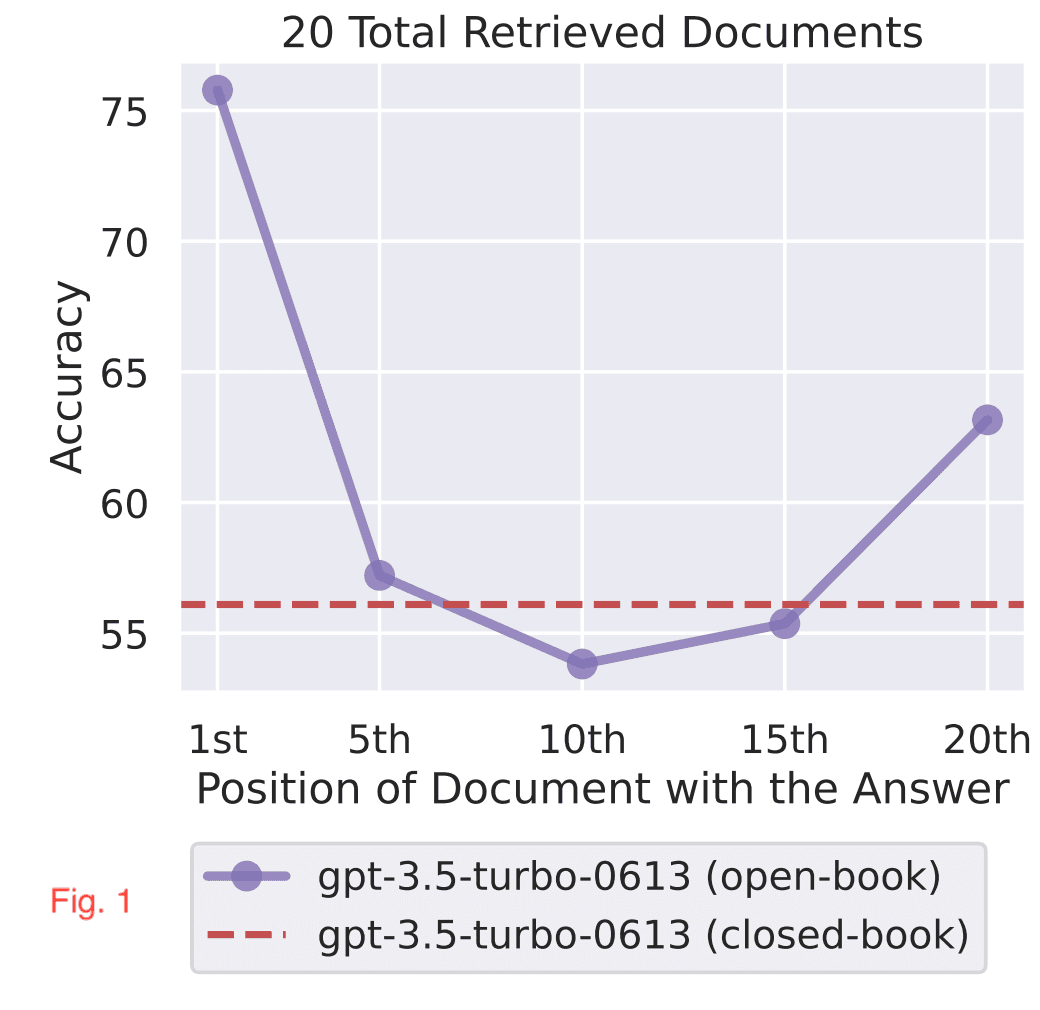
In a recent paper by NF Liu et. al, they discovered to get the best results with RAG (Retrieval-Augmented Generation), you should put the most important documents at the beginning or the end. This is shown clearly in Figure 1, where LLMs are better at using relevant information that occurs at the very beginning or end of its input context,

In the second observation, the accuracy drops as we increase the number of documents as shown in Fig. 2. Hence, the retrieval should only pass a handful of documents to the LLM.

This underscores the significance of document order in the Retrieval part. Here are the things that we can do to increase the accuracy of the Retrieval at the expense of increasing the complexity, cost, and latency:
- Instead of using simple retrieval, try a hybrid of semantic and lexical search.
- Use a Re-ranker as a second stage. So first we select K candidate documents using a retrieval, then re-rank the K document using a ML/DL-based re-ranker.
Reference:
How Language Models Use Long Contexts by NF Liu et. al