Mitigate Prompt Injections
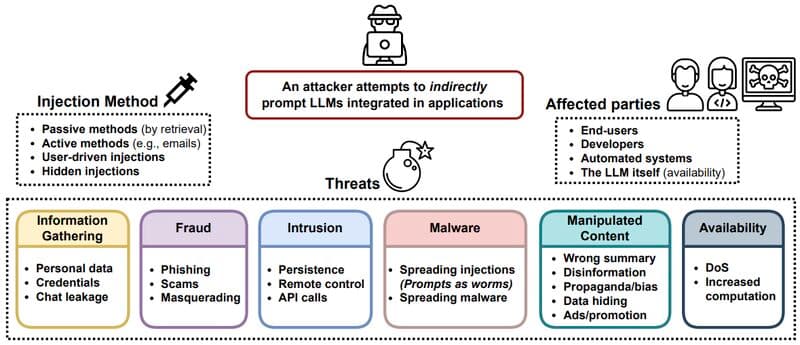
Prompt injections 💉 can manipulate language models like ChatGPT when connected to malicious information sources controlled by attackers. This vulnerability is similar to running untrusted code on a computer, but with natural language instructions for the language model. Despite efforts to mitigate the threat, current solutions only increase the time required to exploit the system, rather than eliminating the risk.
Prompt injection poses a challenge as the prompt can contain data, instructions, or both, reminiscent of familiar computer science issues like SQL Injection. A potential remedy is to separate instructions from data using a special Token, such as BERT's [SEP] token. However, many LLM applications, like ReAct and Chatbots, find this separation challenging.

A viable alternative is to employ two distinct prompts, differentiated by a unique token: one for system-level instructions and another for user inputs. Both can contain instructions and data, but the system prompt should always take precedence. For this to work, models, during their RLHF training phase, must be conditioned to prioritize the system prompt over conflicting user prompts. An example of such a solution is the System prompt in ChatGPT 4, while it’s a step in this direction, remains vulnerable to sophisticated attacks.
Another approach is pre and post-input sanitization, a mechanism that scrutinizes data entering and exiting the LLM to identify malicious content. This sanitization tool can range from a straightforward rule-based system, equipped with a predefined list of blacklisted keywords, to a more advanced machine-learning classifier. Nevertheless, these systems can be outmaneuvered by sophisticated attacks and necessitate regular updates to the machine-learning model or the blacklist to stay abreast of evolving attack strategies.