Model-Based Retrieval System
Information retrieval aims to locate text-based information relevant to a query within a substantial pool of potential sources. In its early stages, sparse retrieval primarily emphasized term matching using sparse representations and inverted indexes like BM25. However, recently, due to the revival of deep learning and the advent of Large Language Models (LLMs), dense retrieval has surpassed traditional sparse retrieval in performance across various tasks.
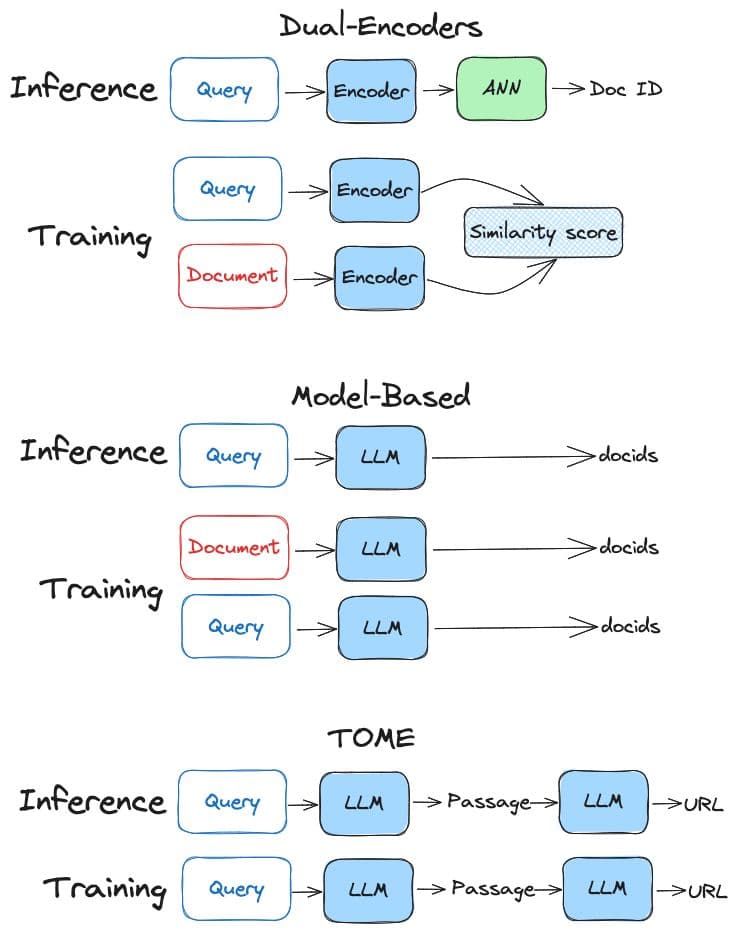
The most well-established type of dense retrieval is called Dual-Encoders. It consists of two identical encoders that convert the text into embeddings. These embeddings are designed to have similar representations for similar input data and dissimilar representations for dissimilar data.

The second type is the model-based originally known as Differentiable Search Index (DSI). This approach involves training a text-to-text model that directly transforms textual queries to the corresponding document identifiers (docids). Basically, the model-based provides query responses solely through its parameters, dramatically simplifying the whole retrieval
Process. That means we don’t need any type of index such as Approximate Nearest Neighbors (ANN). Yannic made two videos explaining this approach (check the references).
A recent research paper called TOME suggests breaking down the Model-based into two stages. It tries to solve the problems introduced by the Model-based such as the discrepancy between pre-training and finetuning, and the discrepancy between training and inference. In the first stage, it generates the passage given the query. which we know that LLMs are good at. The second stage, given passage, it returns the URL. The URLs have semantic meaning compared to docids. Therefore, it is easier for the LLM to generate a URL. Another advantage is the architectural similarity between the training and the inference phase.
However, using model-based comes with costs and limitations. First, using model-based types of architectures for information retrieval can result in high latency due to the computational resources required for processing large amounts of data, making real-time or low-latency applications challenging to implement. The second problem is the index (or model) update, where updating the inverted index or vector database is much easier and faster than model update (model incremental update). Finally, because in the model update, we rely on the model parameters to index the document, the model is prone to hallucination
References:
Transformer Memory as a Differentiable Search Index by Y Tay