No, you don’t need vector search to build your RAG
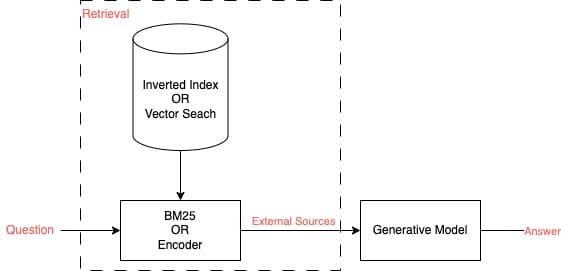
The Retrieval-Augmented Generation (RAG) framework enhances the quality of the Large Language Model (LLM) generated responses by grounding them on external sources, reducing hallucinations or fabricated information. Significantly, RAG allows for the integration of updated information from these sources without the need for re-training the generative model.

numerous online tutorials and examples frequently showcase the use of Embeddings with Vector Search, to build the retrieval part of the RAG framework.
Here I will argue that at least some RAG applications don’t need Embeddings or Vector Search, and a BM25 with an Inverted Index is sufficient if not better.
Computational Efficiency: Lexical matching and BM25 provide computational efficiency, quick responses in large databases, and faster data indexing due to their straightforward nature. On the other hand, an Encoder-based deep neural network is needed to generate the embeddings.
Ease of Implementation: Implementing BM25 with Elasticsearch is straightforward, requiring no specialized neural network knowledge or extensive tuning, making it accessible for teams of varied skill levels.
Transparent and Interpretable: The transparency of lexical matching and BM25, unlike black-box neural networks, simplifies troubleshooting and is crucial for understanding search algorithms in business-critical applications.
Consistent Performance: Lexical and BM25 algorithms deliver consistent, predictable performance across various datasets and domains, often valued in production environments despite not capturing nuanced semantic relationships like neural embeddings.