Vector Search vs. Vector Database
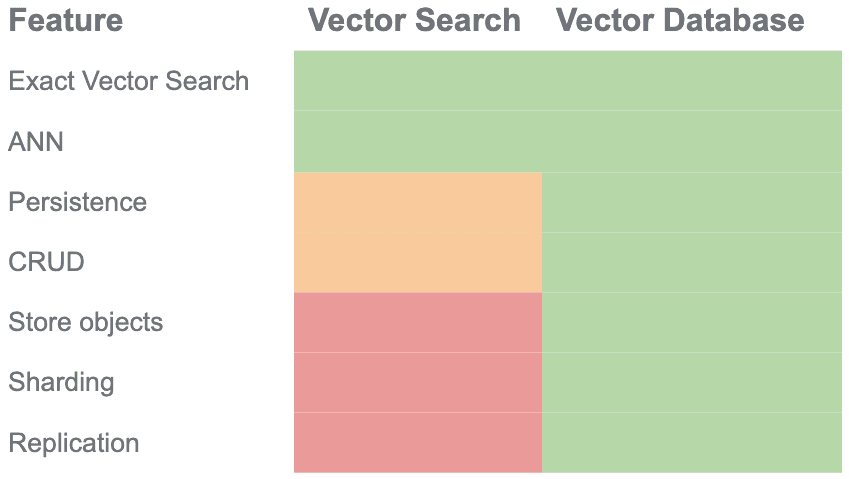
Vector search and vector database share many features and people use the terms interchangeably. But, they aren’t quite the same.
Vector search is a process wherein a query vector is compared against a collection of vectors to find the most similar vectors based on a certain similarity measure (e.g., cosine similarity, Euclidean distance). Its ascendancy can be largely attributed to the progressive advancements in Approximate Nearest Neighbors (ANN) algorithms. These algorithms, by design, prioritize speed over absolute precision, making vector searches considerably faster and more scalable.
Examples of vector search engines are Faiss, Annoy, HNSWLIB, and Google Vector Search (previously known as Matching Engine).

On the other hand, a vector database is a storage system designed to handle vector data efficiently. It provides built-in vector search capabilities along with indexing to speed up search operations. It supports CRUD (Create, Read, Update, Delete) operations even during the importing of the data. Unlike Vector Search, a vector database accommodates various data types, making it more versatile than Vector Search, which primarily handles vectors.
Examples of Vector Search are Qdrant, Milvus, Weaviate, and Pinecone.
Recently, storage and search engines like PostgreSQL, Redis, and Elasticsearch have integrated vector operations within their solutions.